Its holiday season. The wifey is out and what better to do than invest time in reviewing some basic application of machine learning applied to the field of Finance. This is a post I have been wanting to write for a long time. All of the Code has been written in R and is easily reproducible. I will not share it here as I dont know how to do it best. Nonetheless the most important packages for achieving this level of black magic are:
- Caret
- Forecast
- Kenrlab
- Neuralnet
- Xgboost
- tseries (sub to PewDiePie)
I will not be reviewing any of the statistical concepts applied but will merely focus on their application and see if we can find any viable/useful results. I feel I should not be saying this as everyon here is a mature adult. BUT this is no financial advice and you should always be doing you due diligence when investing any of your money, not taking advice from a random stranger in the Internet. And bear in mind just because a strategy has worked in the past does not mean it will work in the future.

We will be taking a closer look at the share price of the german football behemoth from the Ruhrpott who has been the eternal second after Bayern Munich, Borussia Dortmund. As can be decuded the share price is highly related to the clubs sporting. So we shouldn’t be expecting too many conclusive results. The stock has also been known to attract some rather peculiar stories as someone bombing the team bus, hoping to hurt members of the staff to financially benefit from it. The time-seris can be seen below. As can be seen the share price has profited from some healthy growth reahcing an all-time high this year.

But how will proceed? Here a brief overview:
First we will be looking at some feature selection methods such as:
- Filter Methods
- Wrapper Methods
- Embedded Methods
Second we will consider multiple machine learning methods such as:
- Extreme Gradient Boosting Machine (XGB)
- Support Vector Machine (SVM)
- Artifical Neural Networks (ANN)
Third, we will conisder all results and compare them.
After this brief introduction we will finally get our hands dirty. First we will start by simply looking at some feature selection methods. At this point you might be thinking to yourself: “AWWW HELL NAH. JUST SHOW ME HOW TO DO THE THANG” let me tell you that feature selection is one of the most important factors when applying machine learning, so I will briefly run through it. This method consists of simply choosing input predictors. This has multiple advantages such as easy model interpretation, faster learning time, reduced dimensionality and reduced over-fitting. The principal techniques for feature selection are filter, wrapper and ensemble methods.

Filter methods consist of selecting input predictors based on certain statistical criteria before using them in a learning algorithm.
So first we can try to regress the returns of the share price on themselves using linear regression. Then we can trim down the input predictors down using the p-values. So we lagged the returns up to lag 9 (for no particular reason). Only lag 4 is statistically significant at the 5% level. Nonetheless we will also be looking at lag 3 as it still i statistically significant at level 10%. We have an adjusted r-squared value of 0.006 which is a rather poor result. Hence we will be eliminating all the input predictors unless the aforementioned ones.

Re-running the linear regression only using lag 3 and lag 4, we get the summary as can be seen below. As we can see re-running the test with less input predictors yields quite different results. The estimates for the single predictors are now different; furthermore, both of the estimates have become more statistically significant. Additionally the Adjusted R-squared has increased, even though still painfully low.

So we can advance to further ways of selecting our ideal predictor variables. So we can try to find our input predictors wrapper methods. The main advantage of wrappers compared to filter methods is considering interaction with output target features. The downsides of wrapper methods is obviously the increased computational power needed and the risk of over-fitting. Some of the most common Wrapper Methods are:
- Forward selection
- Backward elimination
- Recursive Feature elimination
I personally use backward elimination, where we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.

So using the Caret package we can run this rather simply in R. By the result we can see that the ideal model is composed of four variables, which is able to minimize the mean absolute error (MAE). The lags chosen by the recursive feature selection (rfe) are 4, 5, 1, 7. The results from this little more advanced feature selection is obviously already very different from the results achieved by our simple selection method.

Last but not least we will be looking at embedded methods. These consist of selecting input predictors while using them in learning algorithms and simultaneously maximizing model performance. Embedded methods combine the qualities’ of filter and wrapper methods. It’s implemented by algorithms that have their own built-in feature selection methods. Some of the most popular examples of these methods are LASSO and RIDGE regression which have inbuilt penalization functions to reduce overfitting. I will be using the Lasso regression which performs L1 regularization which adds penalty equivalent to absolute value of the magnitude of coefficients.
Using the Lasso we get a similar result to what we had when we just used the simple linear regression model.

Now that we are done with the feature selection, we can advance to the more juicy stuff.
Going forward we will be using the 4 input predictors we obtained using the recursive feature selection. So this means that we will be using lags 1, 4, 5, 7. Furthermore we will try to run our models via pre-processing our data by using principal component analysis.
So the first machine learning tool we will be using is an Extreme Gradient Boosting (XGB), which is a very commo algorithm (seems to be the favourite from the Kaggle Nerds, joking please don’t boot my nerds). This algorithm is great for supervised learning tasks such as Regression, Classification, and Ranking. EGB has the following parameters.
- Tree boosting algorithm: it predicts output target feature of weighted sequentially built decision trees
- Algorithm optimization: it finds local optimal weight coefficients of sequentially built decision trees. For regression, gradient descent algorithm is used for locally minimizing regularized sum of squared errors function, among others.
Running the XGB in R, this is the output we get. So we notice that the number of rounds which minimized our RMSE was 50 and the max tree depth is 1. This can furthermore be observed when looking at the bottom right window, with eta 0.3 and subsample 1. What we could also try (and which I actually did) is to see whether feature extraction via PCA could improve our results.
![]()
 Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables (entities each of which takes on various numerical values) into a set of values of linearly uncorrelated variables called principal components. This transformation is defined in such a way that the first principal component has the largest possible variance (that is, accounts for as much of the variability in the data as possible), and each succeeding component in turn has the highest variance possible under the constraint that it is orthogonal to the preceding components.
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables (entities each of which takes on various numerical values) into a set of values of linearly uncorrelated variables called principal components. This transformation is defined in such a way that the first principal component has the largest possible variance (that is, accounts for as much of the variability in the data as possible), and each succeeding component in turn has the highest variance possible under the constraint that it is orthogonal to the preceding components.
So quick check if our input predictors are in any shape or form correlated. As we can see none of the input predictors are very much correlated to each other. The most prominent correlation we can observe are at lag 5, which as a positive correlation of 0.08. In this environment using PCA makes not a lot of sense but keep in mind it is a viable tool in a highly correlated environment, such as when checking for interest rate products. Using the PCA pre-processing we finally arrive at an RMSE of 0.02720604 which is actually slightly better than the 0.02723055 RMSE achieved by selection features. Obviously in real-life you would still opt to having as little as possible input predictors. Nonetheless as the results are better and my computer is not suffering too much under the additional computational requirements we will move forward using PCA.

So moving forward, we now will visualize how our residuals behave and try to make sense of our results. Below we can see how our model behaves with respect to the actual time-series of the returns from the share price. The black line represents the actual returns whereas the red line is the estimates from our XGB. You now might be thinking to yourself: “Well this is quite underwhelming…”.

Nonetheless before you rage-quit, keep in mind we want the model to give us directional predictions and not an exact estimate of exactly how much the share price will move. This is exactly what it does, we do not expect the model to reproduce the exact moves of the share, as this would simply mean that the time-series is overfit.

Taking a closer look at the results achieved by the PCA we can see that the results are very similar. Nonetheless the results achieved by pre-processing are much more prominent (simply take my word for this) .

We will now us the model to predict give us a signal and change our position in the stock. We will only consider long or no position, as shorting stocks is just a whole different story.
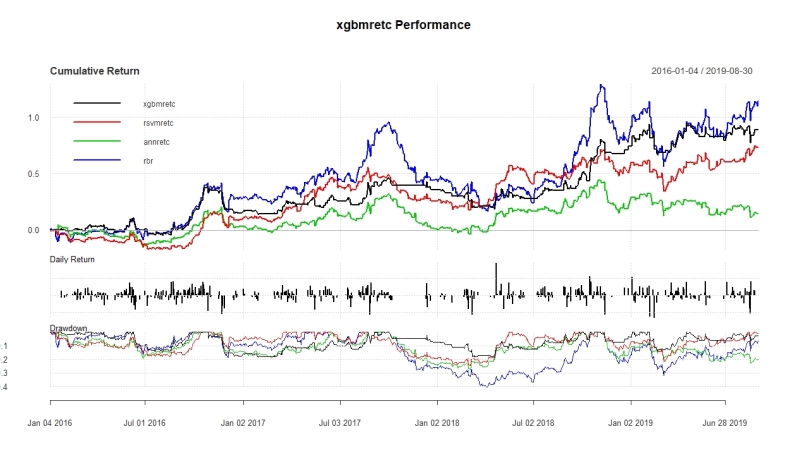
So when running this all we get the following table. The first column “xgbmret” describes simply the returns generated by the model. The second column “xgbmretc” describes the returns generated by the model adjusted for commissions. The commissions were calculated at 10 bps per trade, which actually cuts of fair share or annualized returns. The last column “rbr” simply is the returns generated by a long position. As we can see the model can clearly outperform a simple buy and hold position as it is able to generate higher annualized returns at a much lower risk. Nonetheless the picture changes a little when considering commissions, which place a heavy toll on the performance. When considering any sort of commission, the annualized returns drop by a total of 7 (!!!!!!)percent points. Algebraically it also makes sense that the standard deviation increases. So even though our returns have come down drastically, the Sharpe ratio is still much more performant than a simple buy and hold position.
 Furthermore we can check the equity curve to see how the time-series evolved over time. This is useful information as it will help us infer if any of those performances were just lucky at a certain point in time. By looking at the graph we can see that the performance was quite consistent over time. Additionally it allows to infer one of the big advantages of the model, which is the protection against drawdown which the model ensures.
Furthermore we can check the equity curve to see how the time-series evolved over time. This is useful information as it will help us infer if any of those performances were just lucky at a certain point in time. By looking at the graph we can see that the performance was quite consistent over time. Additionally it allows to infer one of the big advantages of the model, which is the protection against drawdown which the model ensures.
 Ok now that we have tested for this model, let us try some other models. I will be proceeding in a similar way but only present you with the results and spare you all the tedious stuff in between.
Ok now that we have tested for this model, let us try some other models. I will be proceeding in a similar way but only present you with the results and spare you all the tedious stuff in between.
So next we will be looking at Maximum Margin Methods. These methods consist of supervised boundary based learning algorithms for predicting output target feature by separating output target and input predictor features data into optimal hyper-planes. The most common method for regression learning tasks are support vector machines. Support vector machines are usually used for classification tasks which is obviously our case. Here again we will be using the pre-processed PCA time-series, again because the RMSE is lower. I will spare you most of the previously discussed details. Nonetheless I would like to guide your attention toward this graph below. This graph was already discussed when having a more detailed look at the XGB. What we can see now is that the SVM is more volatile when it comes to projections. So even though it might be more accurate but might cost us more money with respect to commissions we will have to pay. 
Here again we can observe what we have observed previously. Nonetheless we can already see that one of the downfalls of the Support Vector Machine is its increased volatility which forces us to change our position many times, forcing us to pay up a lot (hey maybe the broker will send you over some goodies for that). Adjusting for commissions we have to pass on half of our earnings to the broker, which is very hefty. Considering commissions the risk-adjusted performance even becomes worse than the simple Buy and Hold position. This makes clear that it is critical for any signal to be able to blend out random noise. Even though the SVM performed much better than the XGB in an ideal world without commissions, it performed much worse when considering commissions. Now it may be that the commission I am considering is way too high or low, strongly skewing the results. This is the fine balance someone has to consider when setting up any kind of model.

And we can again observe that the trading strategy provides good protection against any sort of downside risk compared to Buy and Hold strategy.

Last but not least we will move on to the Artificial Neural Network (ANN), which is part of the Multi-Layer Perceptron Methods. Multi-layer perceptron methods consist of supervised learning algorithms for predicting output target feature by dynamically processing output target and input predictors data through multi-layer network of optimally weighted connections of nodes. The nodes are usually organised in input, hidden and output layers.

In this case we are running the ANN using the features we selected at the beginning. Just to remind you in case of short-term memory loss, these were lag 1, 4, 5, 7. The results, are to say, at the very least very underwhelming. Even though we were able to bring down the standard deviation net or not of commission the returns are just horrendously bad. This obviously does not de-classify the application of ANN, but it just shows that you don’t need the most complicated of machine learning to be able to solve problems related to finance.


So finally we can compare the results of all the algorithms and see which one performed best. When considering the results generated without considering commissions we get see that machine learning algorithms can provide valuable insights. The only machine learning algo which was not able to outperform the Buy and Hold position was the ANN. As previously mentioned the algos are able to provide some existential protection against downside risk. The retuns generated by any of the rules are anyway rather substantial.
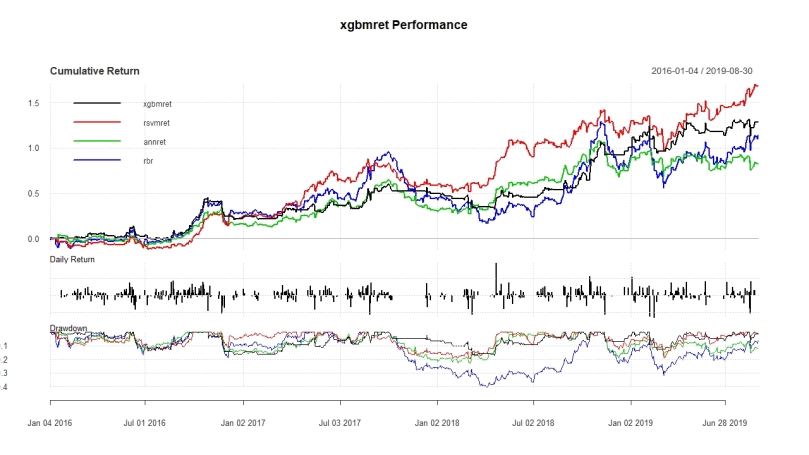
Now ignoring commissions simply is not wise. So the returns worsen a lot when considering commissions. Nontheles we are also able to bring down Std. Dev. drastically, which is a plus. Nonetheless this is still not enough to have a better Sharpe Ratio than the benchmark.